Understand Transformers
Transformers have revolutionized NLP by introducing a powerful architecture capable of capturing long-range dependencies and contextual relationships in text data. This Markdown file provides an in-depth exploration of the Transformers architecture, its components, working principles, and applications.
Overview of Transformers
Transformers are deep learning models specifically designed for sequence-to-sequence tasks, such as language translation and text generation. They were introduced in the seminal paper titled “Attention is All You Need” by Vaswani et al., marking a significant departure from previous sequence models like recurrent neural networks (RNNs) and convolutional neural networks (CNNs).
Key Components of Transformers
- Self-Attention Mechanism:
- Attention Mechanism: Allows the model to weigh the importance of different words in a sentence when predicting each word, enabling it to focus on relevant parts of the input sequence.
- Scaled Dot-Product Attention: Computes attention scores as a dot product of query and key vectors, scaled down by the square root of the dimensionality. Softmax function then converts these scores into weights that determine the amount of attention given to each word.
- Transformer Block:
- Encoder and Decoder Stacks: Transformers typically consist of stacks of encoder and decoder layers.
- Multi-Head Attention: Combines multiple sets of attention mechanisms to capture different relationships in parallel.
- Feedforward Neural Networks: Process the output of attention layers to produce final representations.
- Positional Encoding:
- Embeds the position information of words or tokens into the input embeddings, allowing the model to understand the order of words in a sequence.
How Transformers Work
Transformers operate in two main phases:
Encoding Phase: The input sequence is processed by multiple encoder layers, where each layer applies self-attention and feedforward neural networks to encode contextual information.
Decoding Phase: In sequence-to-sequence tasks like translation, the decoder uses similar self-attention mechanisms along with encoder-decoder attention to generate the output sequence.
Transformer Architecture Diagram
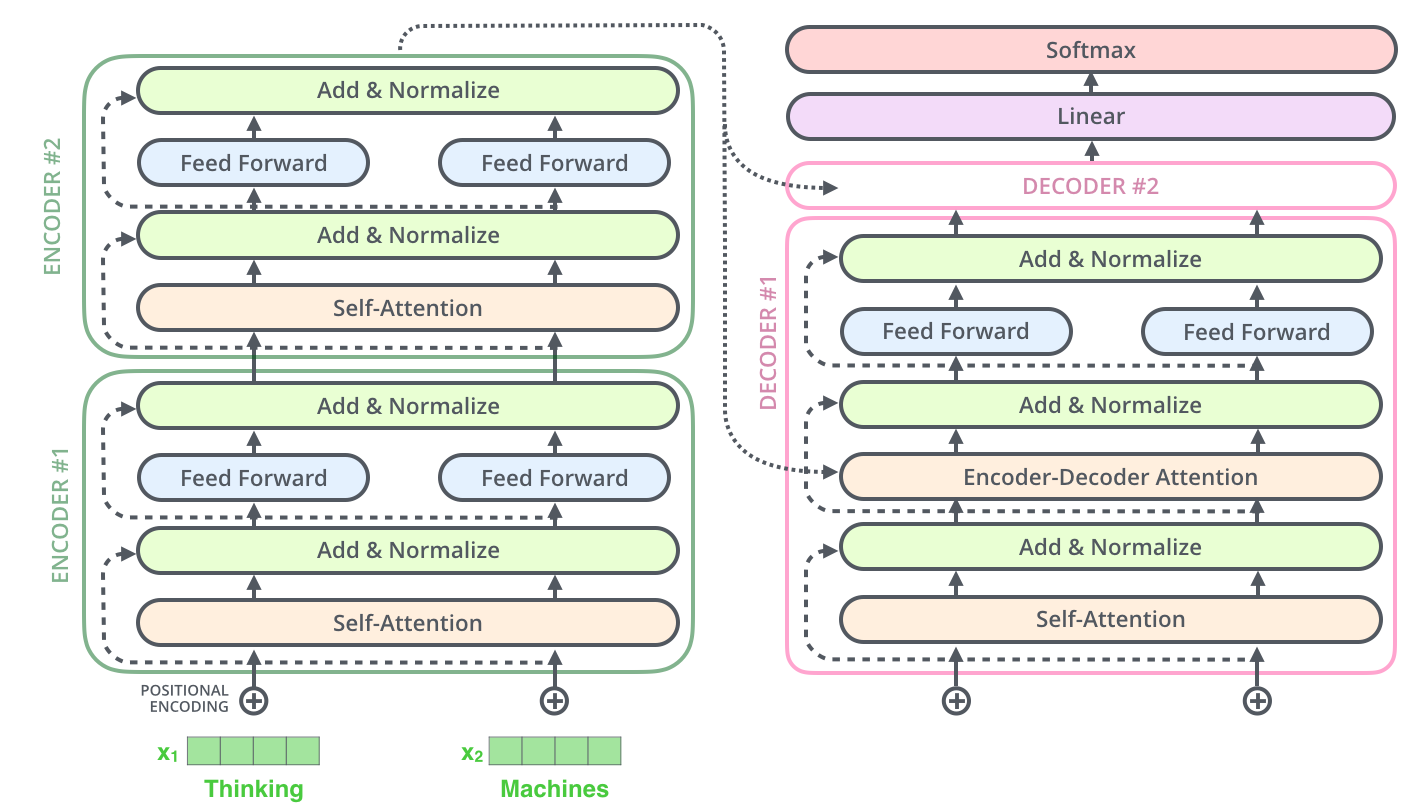
Image Source: The Illustrated Transformer
Applications of Transformers in NLP
Transformers have been applied to various NLP tasks with remarkable success, including:
Machine Translation: Achieving state-of-the-art results in translating between different languages.
Text Generation: Generating coherent and contextually appropriate text, as seen in models like GPT (Generative Pre-trained Transformer).
Named Entity Recognition: Identifying and classifying named entities (e.g., names, dates, organizations) in text.
Advantages of Transformers
Long-Range Dependencies: Transformers can capture dependencies across long sequences of text, making them effective for tasks requiring understanding of context over large spans.
Parallelization: Their architecture allows for efficient parallel processing, improving training and inference speed compared to sequential models like RNNs.
Transfer Learning: Pretrained transformer models can be fine-tuned on specific tasks with relatively small datasets, leveraging knowledge learned from large-scale corpora.
Conclusion
Transformers have emerged as a cornerstone in NLP, facilitating breakthroughs in language understanding, generation, and translation. Their architecture, centered around self-attention mechanisms and positional encoding, enables sophisticated processing of textual data, leading to state-of-the-art performance across various tasks.
Explore further to understand the nuances and advancements in transformer-based models, driving innovation and applications in the field of Natural Language Processing.