Bert Explained
BERT has revolutionized Natural Language Processing (NLP) by introducing a powerful framework for pre-training language representations using bidirectional transformers. This Markdown file explores BERT in depth, covering its architecture, training process, fine-tuning, applications, advantages, and future directions.
Overview of BERT
BERT, introduced by Devlin et al. in the paper “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, represents a breakthrough in NLP by leveraging transformer architecture for bidirectional language modeling. Unlike previous models, BERT can capture context from both directions of a text sequence simultaneously, enabling it to understand language semantics more effectively.
Key Components of BERT
- Transformer Architecture:
- BERT consists of multiple layers of transformer encoders:
- Self-Attention Mechanism: Allows the model to weigh the importance of different words in the input sequence.
- Feedforward Neural Networks: Process information from attention layers to generate final representations.
- Transformer layers enable BERT to capture complex linguistic patterns and dependencies across sentences.
- BERT consists of multiple layers of transformer encoders:
- Pre-training Tasks:
- Masked Language Model (MLM): BERT learns to predict masked tokens within a sentence, forcing it to understand the bidirectional context of words.
- Next Sentence Prediction (NSP): BERT also learns to predict whether two sentences follow each other in the original text, enhancing its ability to understand relationships between sentences.
- BERT Variants:
- BERT Base and BERT Large: Differ in the number of layers (12 layers for base, 24 layers for large) and the number of attention heads (12 for base, 16 for large), affecting model capacity and performance.
How BERT Works
BERT operates through two main phases:
Pre-training Phase: BERT is pretrained on vast amounts of text data (e.g., Wikipedia, BookCorpus) to learn general language representations. During pre-training, BERT learns to predict masked tokens and sentence relationships using MLM and NSP tasks.
Fine-tuning Phase: The pretrained BERT model is fine-tuned on specific downstream tasks, such as sentiment analysis, question answering, and named entity recognition. Fine-tuning involves further training on task-specific datasets to adapt BERT’s representations for specific applications.
BERT Architecture Diagram
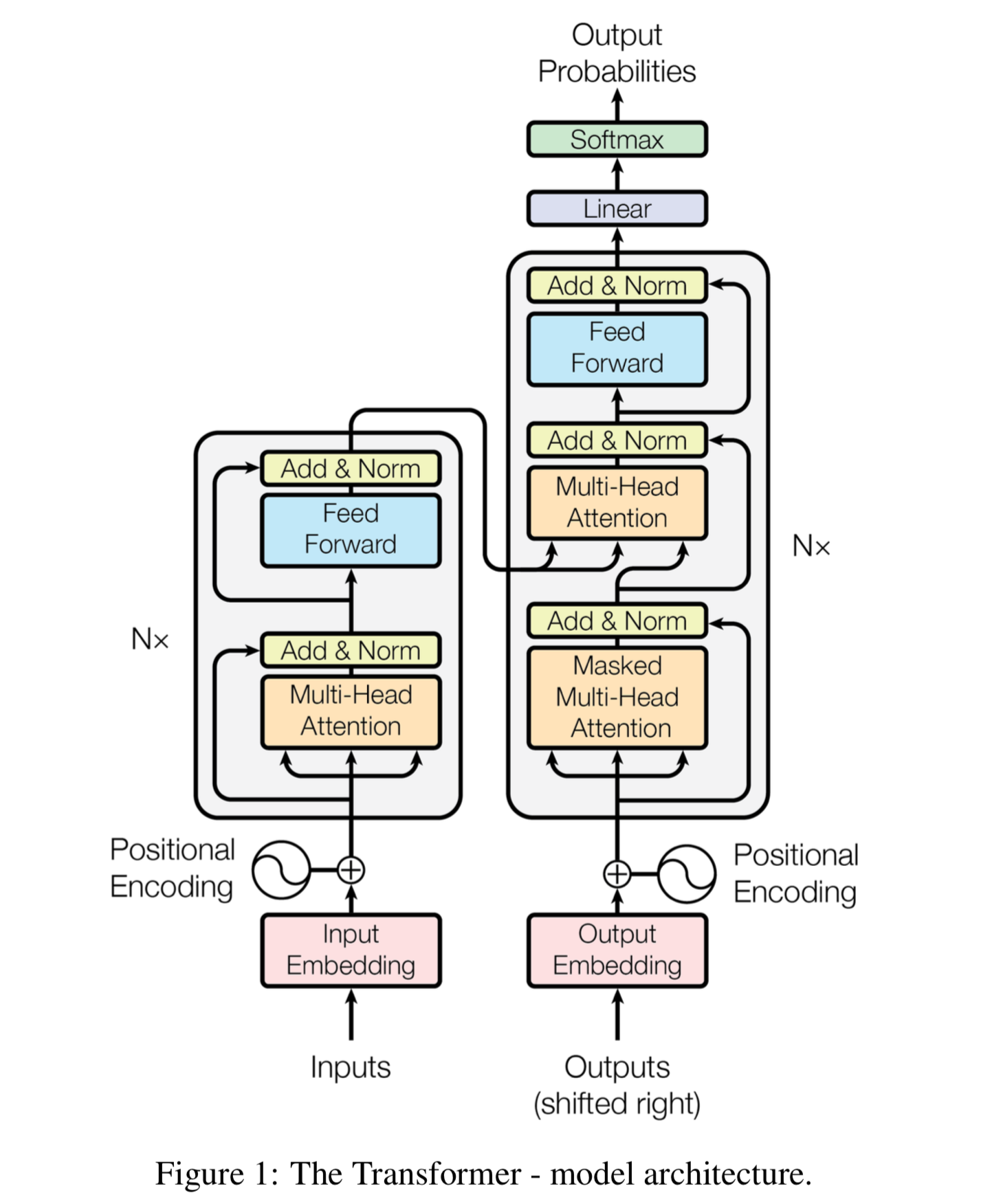
Image Source: Illustrated BERT
Applications of BERT
BERT has demonstrated state-of-the-art performance across a wide range of NLP tasks:
Question Answering (QA): Achieving impressive results on benchmarks like SQuAD (Stanford Question Answering Dataset), where it can accurately extract answers from passages of text.
Text Classification: Classifying text into predefined categories such as sentiment analysis (positive/negative sentiment) or topic categorization.
Named Entity Recognition (NER): Identifying and classifying named entities (e.g., names, dates, organizations) within text.
Semantic Similarity: Measuring the semantic similarity between pairs of sentences, useful in applications like duplicate detection and paraphrase identification.
Advantages of BERT
Bidirectional Context: BERT captures context from both directions of a sentence, enhancing its understanding of word meanings and relationships within text.
Transfer Learning: Pretrained BERT models can be fine-tuned on specific tasks with minimal task-specific data, leading to significant improvements in performance and efficiency.
Language Understanding: BERT excels in understanding nuances in language, improving the accuracy and robustness of NLP applications compared to earlier models.
Challenges and Considerations
Computational Resources: Training and fine-tuning BERT models require substantial computational resources, including high-performance GPUs and large amounts of memory.
Fine-tuning Complexity: Effective fine-tuning of BERT for specific tasks often requires expertise in NLP and careful selection of hyperparameters.
Model Interpretability: Understanding and interpreting decisions made by BERT models, especially in critical applications, remains an ongoing challenge.
Future Directions
Future developments and research directions for BERT include:
Enhanced Model Efficiency: Improving efficiency in training and inference processes to make BERT more accessible and scalable.
Multimodal Integration: Integrating BERT with other modalities such as images and audio for more comprehensive AI systems.
Domain Adaptation: Enhancing BERT’s ability to adapt and generalize across different domains and languages.
Conclusion
BERT represents a groundbreaking advancement in NLP, setting new benchmarks for language understanding tasks through its bidirectional transformer architecture and pretrained representations. Its applications span across various domains, demonstrating its versatility and effectiveness in addressing complex language processing challenges.
Explore BERT’s capabilities and applications further to leverage its potential in advancing AI-driven solutions and innovations in natural language understanding and generation.